Суперкомпьютеры для обучения нейросетей заменили сетью распределенных вычислений
Российские программисты разработали платформу для распределенного обучения больших нейросетей. Она адаптирована для сети из множества разных по мощности компьютеров, любой из которых в любой момент может выйти из процесса. Как и в проектах научных распределенных вычислений, например, Folding@home, такой подход позволяет с помощью множества добровольцев создать сеть, вычислительная мощность которой будет сопоставима с передовыми суперкомпьютерами.
Разработчики описали платформу в препринте, доступном на arXiv.org, а также опубликовали на GitHub код пре-альфа версии.
Эффективность работы нейросетевых моделей во многом зависит от их размера и от размера обучающей выборки. Например, лидирующая на момент написания заметки модель обработки естественного языка — GPT-3 — имеет 175 миллиардов параметров и была обучена на 570 гигабайтах текстов. Но для обучения подобного масштаба требуется соответствующая вычислительная мощность, которая из-за дороговизны зачастую недоступна исследовательским группам, не входящим в состав крупных IT-компаний.
Во многих областях науки есть проекты распределенных вычислений, решающие эту проблему с помощью волонтеров: любой человек с доступом к интернету может установить у себя программу, которая будет в фоновом режиме проводить нужные ученым вычисления. Вместе, тысячи или даже миллионы компьютеров бесплатно предоставляют ученым вычислительную сеть с мощностью лидирующих суперкомпьютеров: в 2020 году мощность сети биомолекулярных симуляций Folding@home перешла рубеж в один экзафлопс и продолжила расти.
Но сети распределенных вычислений имеют недостатки: каждый компьютер может в любой момент отключиться или передавать данные медленно и нестабильно, а кроме того, не все типы вычислений одинаково легко разбиваются на подзадачи для распределения по отдельным вычислительным узлам.
Максим Рябинин (Maksim Riabinin) из Высшей школы экономики и Яндекса вместе с коллегой Антоном Гусевым (Anton Gusev) разработали платформу Learning@home, позволяющую распределять обучение нейросетевых моделей на множество компьютеров. В основе платформы лежит метод коллектива экспертов, при котором за обработку разных входящих данных отвечают определенные «эксперты» — отдельные алгоритмы или компьютеры.
Разработчики предложили разбивать слои обучаемой нейросети на набор экспертов. Каждый из экспертов может иметь свою специализацию, к примеру, выступать в качестве части нейросети сверточного или другого типа.
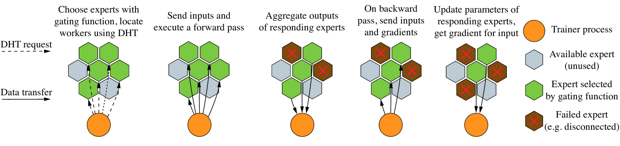 Схема работы сети / Maksim Riabinin, Anton Gusev / arXiv.org, 2020
Схема работы сети / Maksim Riabinin, Anton Gusev / arXiv.org, 2020
Сеть компьютеров для обучения или выполнения нейросетевых алгоритмов имеет децентрализованную структуру, а каждый из ее вычислительных узлов состоит из трех частей: исполняющей среды, управляющей части и DHT-узла. Исполняющая среда непосредственно отвечает за вычисления, то есть выступает в качестве эксперта. Управляющая часть принимает входящие данные, выбирает подходящих для их обработки экспертов и собирает данные вычислений. А DHT-узел — это часть распределенной хэш-таблицы, в которой сеть хранит свои данные.
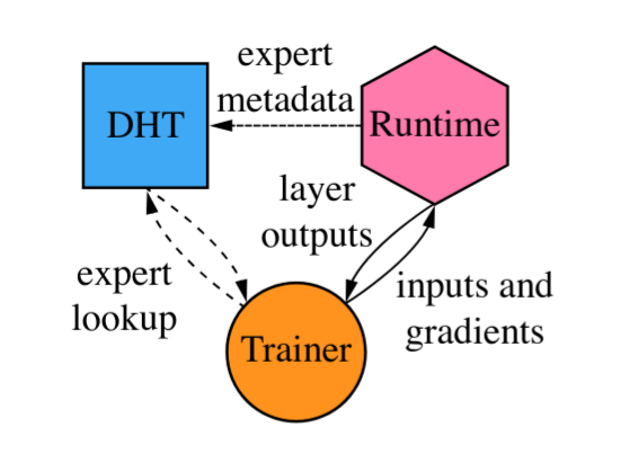 Схема узла сети / Maksim Riabinin, Anton Gusev / arXiv.org, 2020
Схема узла сети / Maksim Riabinin, Anton Gusev / arXiv.org, 2020
Авторы опубликовали код, который они использовали для первичной проверки работоспособности платформы, на GitHub, но отметили, что пока его не стоит рассматривать как готовую к использованию библиотеку. Также они отметили, что платформа в нынешнем виде будет иметь типичные недостатки одноранговых сетей, в том числе высокую нагрузку на сетевую инфраструктуру, а также подверженность специфичным для такого сетей атакам, возможность которых произрастает из их архитектуры, а не конкретной реализации.
- Источник(и):
- Войдите на сайт для отправки комментариев
