Microsoft представила небольшую модель Phi-2, которая лучше «старших сестёр». Что это за проект?
Блог компании МТС. Автор: @divolko3. T-компании сейчас создают различные языковые модели, стараясь превзойти друг друга. Одна из таких организаций — корпорация Microsoft. Не так давно она представила модель Phi-2, при этом разработчики утверждают, что она равна илипревосходит гораздо более масштабные проекты. Подробности — под катом.
Что это за модель такая от Microsoft?

Называется она Phi-2 и насчитывает около 3 млрд параметров. Если быть точными, то 2,7 млрд. Несмотря на то, что модели других компаний превосходят её по количеству параметров во много раз, Phi-2 может с ними конкурировать. Более того, опережать их по результатам прохождения ряда бенчмарков.
Если говорить о языковых моделях, то бенчмарки позволяют тестировать модели на способность к общим рассуждениям, а также пониманию языка, решению математических задач и генерации кода, причём весьма сложного. Например, модель от редмондской компании такая же производительная, как Mistral, которая разработана Mistral AI. Она насчитывает свыше 7 млрд параметров. Есть ещё одна — её название Llama-2, создана она Meta Platforms и включает от 7 до 70 млрд параметров в зависимости от версии.
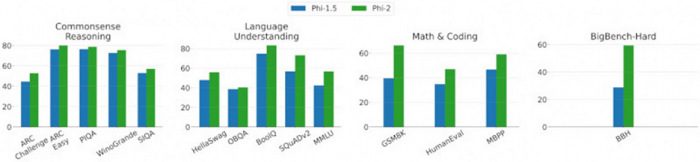
Что касается последней, то в ходе тестов на математические операции модель от Microsoft уступает лишь Llama-2 с 70 млрд параметров. При этом при работе с кодом она обходит большинство конкурентов. Не отстаёт она и в отношении других тестов. В СМИ уже прозвучала мысль, что, наверное, возможности языковых моделей не напрямую зависят от их размеров, раз уж Phi-2 настолько хороша. Но здесь, как всегда, есть нюанс.
Так в чём секрет?
По мнению специалистов, высокая производительность модели напрямую связана с отличным качеством данных, на которых она обучалась. В Microsoft эти данные подбирались для обучения своей модели логике и представлениям о «здравом смысле», что бы это ни значило для машины. Получается, что при минимуме данных авторам проекта удалось достичь максимума возможностей. Кроме того, они смогли добиться высоких показателей без применения метода подкрепления.
При его использовании применяется «ручная» проверка результатов. Если что-то не так, эксперты донастраивают модель самостоятельно. В целом, именно этот метод используется в большинстве проектов. А вот представители Microsoft нашли возможность обойтись без него. Причём модель смогла обучиться нейтральности и отсутствию «токсичности» по сравнению с другими проектами.
Также не использовались и методы инструкционной настройки (instructional tuning), что даёт возможность эффективно минимизировать проявления предвзятости и снижать риск токсичных выходных данных. Всё это делает Phi-2 одной из наиболее безопасных и этичных моделей в сфере ИИ.
Так, Phi-2 обходит по результатам бенчмарков своего прямого конкурента — модель Gemini Nano 2, проект от Google. В неё входит 3,2 млрд параметров. На данный момент эта модель самая производительная, её разработали для работы на смартфонах и других устройствах. Основная задача — «осмысление» текстов, их корректирование и адекватное общение с пользователями.
Стоит отметить, что Phi-2 — лишь один из этапов реализации проекта по созданию малых языковых моделей от корпорации Microsoft. Первая модель этой серии, Phi-1 с 1,3 млрд параметров, вышла ранее в этом году и была нацелена на задачи разработки на языке Python. В сентябре представлена Phi-1.5 с аналогичным количеством параметров, но обученная на новых данных, включая синтетические тексты, созданные с помощью программирования на естественном языке.
По мнению специалистов, модель от Microsoft — новое слово в машинном обучении. Phi-2 предоставляет дополнительные возможности разработчикам и исследователям из разных стран. Также этот проект можно назвать стимулом для развития всей отрасли.
А что у Google?
Корпорация Google совсем недавно представила мультимодальную модель ИИ, которую называет конкурентом GPT-4 от OpenAI. Она умеет обрабатывать текстовую, аудиоинформацию, изображения и видео.
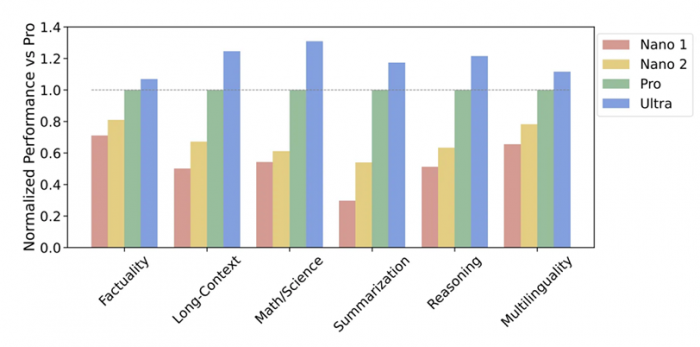
На текущий момент есть три версии Gemini:
Ultra — флагманская модель с максимальными возможностями. Именно она показывает самую высокую производительность в сложных задачах, включая анализ и работу с несколькими модальностями. На её основе планируется запустить продвинутую версию чат-бота Bard Advanced. Ultra будет доступна лишь в 2024 году.
Gemini Pro — версия среднего уровня для более широкого круга задач. Она стала основой Google Bard. Позволяет генерировать тексты и изображения, задавать вопросы и искать информацию. Чат-бот с Pro-версией модели сейчас доступен в 170 странах, правда, пока только на английском языке. Доступ к Pro-версии могут получить корпоративные клиенты Google и разработчики через API на платформах Google Generative AI Studio и Google Cloud Vertex AI начиная с 13 декабря.
Gemini Nano — это наиболее базовая версия, которая предназначена для локального применения на мобильных устройствах. Она будет доступна для пользователей на смартфонах Google Pixel 8.
Основные озвученные разработчиками модели преимущества: большая гибкость Gemini по сравнению с конкурентами, возможность работы с ИИ без подключения к интернету, а также бесплатный доступ к продвинутым функциям (что, вероятно, актуально на время тестирования Gemini). В целом, моделей становится всё больше, конкуренция выше, так что, возможно, скоро мы увидим ещё одно «новое слово» в ИИ-отрасли.
- Источник(и):
- Войдите на сайт для отправки комментариев
