GigaSearch или Поисковая система на GigaChat
Блог компании Сбер. Автор: Прохор Гладких. Галлюцинации — это явление, которое до недавнего времени было привилегией человеческого сознания. Однако, с развитием текстовых генеративных моделей, таких как GigaChat и ChatGPT, возникла возможность наблюдать подобные «иллюзии» и в мире искусственного интеллекта.
Есть случаи, когда галлюцинации генеративной модели вполне уместны. Например, если вы попросите модель сгенерировать детскую сказку, то наличие в ней выдуманных персонажей и событий будет весьма кстати и понравится малышу.
Проблема галлюцинаций генеративных моделей
Совсем по-другому дело обстоит при вопросах, например, касающихся реальных людей или событий. Тут пользователю хочется получить ответ, в первую очередь, основанный на фактах.
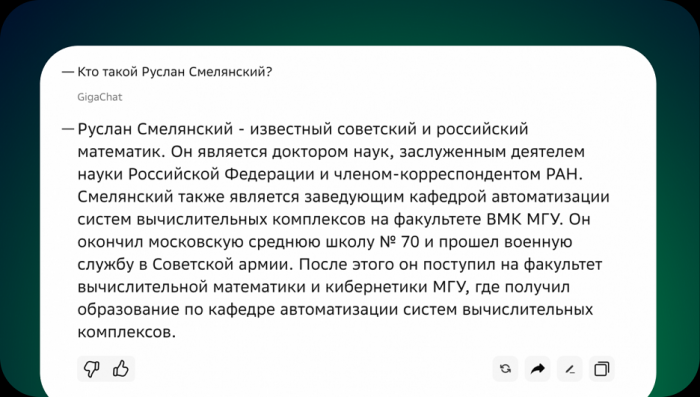 Пример фактологически точного ответа GigaSearch
Пример фактологически точного ответа GigaSearch
Но, к сожалению, современные генеративные модели часто искажают или придумывают несуществующие факты в своих ответах. Причем, самое интересное, что делают они это очень искусно, и по ответу зачастую нельзя понять, придумала модель данное событие или оно действительно имело место быть.
Например, недавно ChatGPT придумала сексуальный скандал, а нарушителем указала реального профессора, сославшись на несуществующую статью в известном журнале. Все это оказалось чистейшей выдумкой, а упомянутый профессор никогда не обвинялся ни в чем подобном.
 Заголовок статьи The Washington Post о галлюцинации ChatGPT
Заголовок статьи The Washington Post о галлюцинации ChatGPT
Откуда берутся галлюцинации генеративных моделей
Так почему же большие генеративные модели придумывают несуществующие факты? Все дело в том, что в общении человек основывает свои рассуждения на определенных точках в своей памяти, которые он сам может оценить на достоверность. То есть, если человек упоминает какой-то факт, в котором он не уверен или помнит неточно, он знает об этом и выскажет своему собеседнику неуверенность, используя слова «возможно», «скорее всего» или другие.
Модель же, с другой стороны, не имеет способности оценивать достоверность фактов, которые сохранились в ее весах. Каждое следующее слово генерируется статистически, как наиболее вероятное, при этом, проверять фактологичность получившегося заявления без использования внешних источников знаний ученые пока не научились.
Проблема обрезки знаний
Другой известной проблемой чат-бот моделей является неосведомленность о последних событиях в мире. В моделях GigaChat и ChatGPT, на текущий момент, знания ограничены примерно серединой — второй половиной 2023-го года. Дата ограничения знаний — это дата, когда был сделан этап предобучения моделей. Обо всем, что произошло после этой даты, модель знать не будет. Как известно, этап предобучения — очень ресурсоемкий и длительный по времени. Он может занимать несколько месяцев, при этом в нем используется большой кластер видеокарт. То есть полностью переобучать большую модель — дорого и долго, поэтому отставание по свежести информации есть у всех больших языковых моделей.
Для пользователей это означает, что модель может выдавать информацию, которая уже устарела. Например, на вопрос о последней модели iPhone, чат-бот может выдать информацию про предыдущую.
Решение с помощью RAG
Над решением проблем галлюцинаций и отставания во времени по знаниям в генеративных моделях ученые бьются довольно давно.
- Источник(и):
- Войдите на сайт для отправки комментариев
