Взлом и обфускация ДНК. Guest Post
Автор: Олег Сивченко. Мой первый пост на Хабре (демо-версия авторского хабротекста из разряда «а может, взлетит»?) был посвящен сходству ДНК и программного кода. Такая тема казалась мне максимально «канонической» и «соответствующей тематике Хабра», но при этом непритязательной. Кроме того, я тогда действительно зачитался книгой Сергея Ястребова «От атомов к древу», а начинать со статьи о серповидноклеточной анемии и муковисцидозе, которые во времена повальной малярии и туберкулеза были скорее фичами, чем багами (немножечко увеличивая выживаемость и репродуктивные шансы больного на фоне популяции) — не решился.
Тем не менее, до самого последнего времени я ощущал, что тема кода и ДНК требует гораздо более серьезного и профессионального поста, чем мог бы написать я сам. Поэтому я обратился за помощью к уважаемой Анастасии Новосадской @anastasiamrr , давно желавшей попробовать свои силы на Хабре, и с удовольствием и благодарностью размещаю в блоге её интереснейшую статью о вредоносном генетическом коде и методах его маскировки. Добро пожаловать под кат.
В этой статье речь пойдет о коде, причем не программном, а генетическом. Выражение «генетический код» стало настолько расхожим, что многие и не задумываются о том, насколько на самом деле похожи биологический код и программный, и какие схожие уязвимости для них характерны. Код — это система знаков, расположенная в определённой последовательности для хранения и передачи какой-либо информации. Он может быть штриховым, радиогенетическим, программным, цифровым. И если генетический код — это основа биологической жизни, то программный в XXI веке проник во все ниши общества на волне цифровизации. Софт буквально повсюду: смартфоны, фитнес-трекеры, рекламные LED-экраны, принтеры, автоматизированные производства. Можно сказать, что программный код в каком-то смысле начал управлять нашей жизнью.
А вместе с ним в нашу жизнь вошли киберпреступники — люди, желающие взломать чужой код, скопировать и похитить, т.п. Дело в том, что аналогично им существуют различные организмы, которые способны совершить то же самое с генетическим кодом других клеток и многоклеточных организмов. Таким образом вирус, бактерия, а порой и клетка своего организма (речь сейчас как раз о раковых клетках) может заставить других работать на себя или скопировать особенности чужого кода. Об особенностях программирования и реализации кода клеток как раз и написано в данной статье.
Прежде, чем начать, стоит провести короткий ликбез для всех малознакомых с наукой о жизни нашей:
Вирус — неживая частица с генетической информацией, которая может заражать живые клетки и менять их ДНК-код.
Патоген — бактерия, вирус или что угодно другое, что вызывает болезнь.
Клетка — мельчайшая, но самостоятельная живая единица организма. Имеет свои аналоги с ПК такие, как ввод/вывод информации, хранение, передача.
Опухолевая клетка — дефектная клетка организма, такой своеобразный «бунтарь» и «борец с системой». У них есть способность к бесконтрольному делению , также они становятся атипичными для своего организма.
В программировании для борьбы с такими «злоумышленниками» используют обфускацию — намеренное запутывание кода, при котором он сложен для понимания человеком, но при этом функционально ничуть не меняется.
Удивительно, что код программный был написан гораздо раньше, чем люди узнали о том, что все живые организмы также основаны на коде генетическом: Ада Лавлейс, которую считают первым профессиональным программистом, написала код для вычислительной машины уже в 1843 году, а идея о существовании генетического кода была сформулирована и высказана в 1950-х Даунсом и Гамовым, т.е. спустя 110 лет.
В нашем организме предусмотрены всевозможные варианты обфускации генетического кода, чтобы никакие вирусы, бактерии, «мятежные» опухолевые клетки не смогли помешать нормальному функционированию организма. Только вот в живой природе обфускация идёт не столько на уровне генетического кода, сколько на уровне его продуктов — белков. Белки задействованы буквально ВЕЗДЕ: от считывания кода ДНК и РНК (полимеразы, хеликазы, белки, формирующие рибосомы) до клеточного «общения» (большинство сигнальных систем клеток построено как раз на белках) для регуляции слаженной совместной или одиночной работы. Такое «общение» можно сравнить с работой по локальной сети или же на ПК. А наш организм, по сути, подобен Интернету: каждые отдельные клетки — это хосты, нервные клетки — оптоволокно, скопления нервов — серверы и ЦОД. Как и в реальном интернете, перечисленные узлы могут быть подвержены атакам вредоносных агентов, которыми могут быть вирусы, бактерии и иные организмы. Очевидно, что наш организм знает не только, как защититься от врагов, но и как им противодействовать, ловко пользуясь созданными за миллиарды лет эволюции подходами. (Например, защищаться от белковых DDoS-атак).
Однако биологические зловреды тоже не так просты, и могут пользоваться не только созданным самостоятельно инструментарием для «взлома» клетки, но и использовать то, что атакуемая клетка когда-то создала для себя. Например, вирусы способны пользоваться ферментами инфицированной клетки для сборки новых вирусных частиц, могут встраивать свои генетические программы прямо в геном клетки и размножаться вместе с ней практически бесплатно, находясь в таком спящем состоянии до определённого момента. Такие биологические стилеры находятся в каждом из нас, и мы начинаем замечать их только тогда, когда наша иммунная система слегка ослабляет хватку, например, когда мы проходимся по холодной улице без шапки.
«Преступники» могут точно так же перепрограммировать код наших клеток, порабощая их, как компьютерные вирусы перепрограммируют компьютеры для такой же цели. Когда в организм попадают патогены, наши иммунные клетки, выполняющие функции антивирусного софта, сканируют свойства этих бактерий и вирусов, чтобы понять их потенциальную опасность. А свойства-то обфусцированы! В ходе эволюции велась своего рода «холодная война» между организмами и их «врагами» (патогенами). Она заключалась в том, чтобы запутать код и придумать лазейки для распутывания кода оппонента как можно быстрее. Таким образом, поколение сменяется поколением, а борьба за попытку взломать код друг друга максимально быстро и с минимальным количеством издержек продолжается и будет продолжаться. И если у кого-то получится приобрести невозможную для расшифровки обфускацию, то противодействующая сторона окажется в проигрыше и, скорее всего, вымрет.
Принцип работы генетического кода
Для того, чтобы понимать, какие варианты обфускации применяются в клетках и как их обходят, нужно разобраться с тем, что же за генетический код такой и чем он схож с программным, а может, и отличается от него.
Разберем ситуацию на классическом примере двоичной системы счисления. У машины есть электрические сигналы: 0 — сигнала нет, 1 — сигнал есть. Представим, что у нас есть машина, в которой сигналы записываются на магнитную ленту в двоичной системе. У живых же организмов информация хранится в виде биохимических молекул (ДНК, например, обладает отрицательным зарядом. Это важно для того, чтобы к ней присоединялись специфичные белки и регулировали экспрессию (реализацию) генетического кода), и если у машин это 2 позиции, то у нас — 4. В молекуле ДНК это четыре нуклеотида (азотистых основания): аденин (А), тимин (Т), гуанин (Г), цитозин (Ц).
Есть ещё такие основания, как урацил (У), инозин (И) и др., которые возникают при копировании/переписывании информации с ДНК на ДНК/РНК, что необходимо, чтобы повысить стабильность самой ДНК. Ферментные системы контроля распознают такие основания и удаляют в случае копирования информации с ДНК на ДНК, т.к. это считается ошибкой (необходимо для деления клетки). Если же происходит переписывание с ДНК на РНК, то разные азотистые основания не являются ошибкой, а не позволяют произвести гибридизацию РНК с ДНК, что аналогично запрету на редактирование и разрешению на чтение соответственно. Этим же запретом на редактирование организм препятствует попаданию вирусов в свой геном.
Вернемся к нуклеотидам. Они идут в определённом порядке, образуя ДНК. По сути, саму спираль ДНК можно сравнить с магнитной лентой, но с той особенностью, что если на магнитной ленте записан код в двоичной системе счисления, то в ДНК — четверичной. На первый взгляд, разница колоссальная, а на второй и третий математический — нет. :)
Компьютер в своей логике оперирует минимальными кодирующими единицами – битами, которые объединяются в кодирующие группы – байты. За счёт такого разделения удается закодировать необходимую информацию и удобно работать с ней.
Удивительно, но аналогичная логика работает и в нашем организме. У организма биты заменяют нуклеотиды, а байты — кодоны. То, что система счисления в нашем организме четверичная, позволяет сделать генетический код более ёмким при меньшем объёме, что играет большую роль при копировании информации, поскольку это сугубо биохимический процесс. И если у машины 1 байт равняется 8 битам, то у организма 1 кодону соответствуют 3 нуклеотида. Одна тройка нуклеотидов кодирует одну аминокислоту, включаемую в белок, а также обозначает начало и конец трансляции (синтеза белка).
Важно отметить одно из свойств генетического кода (специфичность): один кодон соответствует только одной аминокислоте, а одна аминокислота может кодироваться несколькими кодонами. Аминокислоты объединяются в белок, который имеет свои функции в зависимости от последовательности кодонов и их типов. Также белок может постфактум редактироваться, чтобы принять необходимую конформацию (форму) и/или приобрести дополнительные функции. Эти процессы называются «фолдинг» (приобретение формы) и «посттрансляционные модификации». Их можно сравнить с использованием декораторов в Python. Если представить получившийся белок как функцию, то способ, позволяющий изменить её поведение, не меняя её код — это применение декораторов, которые будто обёртывают исходную функцию. Благодаря такому врапперу белок-функция приобретает новые свойства, которые нередко являются ключевыми для организма.
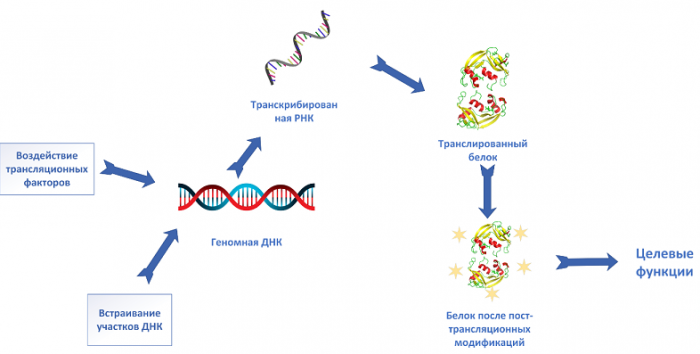 Схема реализации генетического кода
Схема реализации генетического кода
Ближайший аналог белка при сравнении его с исходным кодом — это программа для вывода файла на печать либо для конвертации файлов из одного формата в другой. Логика такова: из кода была извлечена информация, преобразованная вывелась в человеко-читаемый или, в нашем случае, «организмо-читаемый» формат.
Вкратце о переменных в коде. В исходном коде есть разные типы переменных: для обозначения массивов, чисел с плавающей запятой и прочих структур данных. Переменные могут занимать довольно большое количество байтов, чтобы вместить достаточное количество информации для реализации команды. И снова в ДНК то же самое! Переменная — это ген. Целая компьютерная программа кодируется огромнейшим количеством байтов и логических конструкций, и в клетке роль такой программы выполняет геном.
Ещё одно свойство генетического кода, для более подобного описания которого был написан этот пост на Хабре, — универсальность. Генетический код един для всех организмов. Абсолютно. Вообразите, будто все программисты внезапно начали писать код на одном языке. И есть логичное объяснение, почему практически все организмы имеют одинаковый генетический код (и нет, горе креационистам, это не из-за божественного вмешательства).
Для этого нужно вернуться на 3,5 миллиарда лет назад, когда древние организмы только начинали обзаводиться тем разнообразием биологических инструментов, которое мы имеем сейчас. Как известно, эволюция движется за счёт двух основных факторов: мутаций (случайных изменений в генетическом коде) и естественного отбора. В случае, если какой-то организм получал мутацию, которая меняла логику кодирования генетической информации, данный организм терял возможность пользоваться всем тем многообразием инструментов, которые он уже развил. Это приводило к тому, что он быстро погибал и не мог передать свою мутацию потомкам. Такой эволюционный механизм можно сравнить с процедурным программированием, где всё громоздится в один большой кусок и, если впоследствии появляется необходимость в изменениях, то их внесение становится проблемой. Причём сложность приобретения значимых преобразований растёт экспоненциально с размером кода.
Поэтому кодирование информации в организме — это своеобразный костыль, поставленный несколько миллиардов лет назад, но, как ни парадоксально, всё ещё работающий. Более того, некоторые организмы в процессе эволюции могли делиться между собой генетической информацией, а за счёт того, что код одинаков, он «вставал» без особых проблем. Улавливается сходство с github-репозиторием?
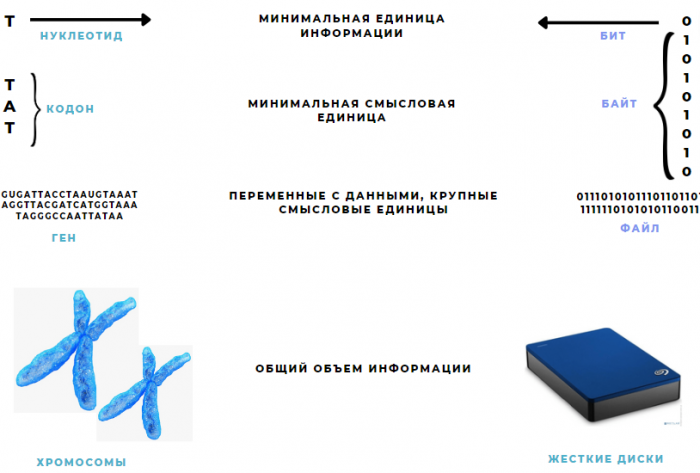 Принципиальное сходство программного и генетического кода
Принципиальное сходство программного и генетического кода
Таким образом, мы разобрали, в чём наиболее схожи генетический и программный код. Можно заметить, что сходств уже достаточно много, но при более детальном разборе их окажется в несколько раз больше. Учёные даже смогли в бактериальной клетке закодировать ту самую фразу «Hello world». Бактерия использовалась как носитель информации, та же флешка, только живая. Вот тут можно об этом почитать. Теперь, разобравшись во всём контексте, переходим к основной теме статьи.
- Источник(и):
- Войдите на сайт для отправки комментариев
