Могут ли компьютеры изобретать? Создаем аналог ТРИЗ на нейронных сетях архитектуры Трансформер
Автор: Сергей Гурылев. Современные языковые модели достигли впечатляющих результатов в некоторых задачах, которые раньше были под силу только человеческому разуму. Так, например, некоторые модели могут без затруднений искать ответы на вопросы, сформулированные на естественном языке в огромных массивах текстовой информации, при этом они не «подсматривают» во внешние источники, а хранят все знания в своей памяти (например, некоторые модели архитектуры T5).
Можно пойти дальше и задаться целью создать языковую модель для решения специфичной изобретательской задачи, которая может стоять перед техническим экспертом. В рамках данной публикации попробуем ответить на вопрос, могут ли современные нейронные сети генерировать решения изобретательских задач по описанию текущего состояния технической системы и проблемы, которую необходимо устранить в рамках системы.
Текст данной публикации является переработанным кратким изложением основных моментов магистерской диссертации, которую я защитил не так давно. Здесь приведена та часть текста, которая содержит новизну в плане подхода к решению изобретательских задач с использованием глубоких нейронных сетей. Захотелось поделиться с сообществом результатами эксперимента, возможно читатели Хабра найдут их полезными. Можете пропустить введение, если вас интересует исключительно практическая сторона вопроса.
 Концептуальная схема вопроса
Концептуальная схема вопроса
Введение
Начало XXI века принесло с собой одну новую особенность общественного устройства – переход к экономике, основанной на знаниях, отличительной чертой которой является интенсивное развитие секторов, связанных с нематериальной деятельностью. В мире возникает принципиально новая система создания общественного богатства, в основе которого – исследования и инновации. В развитых регионах от 70 до 85% прироста валового внутреннего продукта приходится на продукцию, созданную с использованием новых знаний. Иными словами такую экономику называют экономикой знаний.
По мнению некоторых исследователей, переход к экономике знаний будет сопровождаться вступлением человечества в эпоху четвертой промышленной революции. Эпоха четвертой промышленной революции будет ознаменована внедрением интеллектуального анализа больших данных, концепции интернета вещей, суперкомпьютерных вычислений. В конечном счете предполагается, что это приведет к тому, что автономные вычислительные устройства будут обмениваться данными друг с другом и взаимодействовать с окружающим миром, используя ту информацию, которую удалось получить в процессе интеллектуального анализа.
В целом можно сказать, что дальнейший рост инновационных экономик будет сильно связан с принципиально новыми возможностями, которые принесет четвертая промышленная революция. Если будущее развитие человечества будет связано с интеллектуальным анализом данных и постоянным поиском инновации, то возникает вопрос: почему бы не доверить техническое совершенствование одних машин другим машинам? Человечество в течение нескольких десятилетий пытается придумать методы изобретательского мышления, в надежде формализовать и/или ускорить изобретательский процесс. Было разработано несколько методик творчества, пожалуй, среди них можно выделить наиболее известные — метод мозгового штурма, латеральное мышление, метод фокальных объектов, ТРИЗ (теория решения изобретательских задач). Большинство данных методов по уровню научной проработки находятся рядом с популярной психологией, и не предлагают ничего нового кроме различных модификаций комбинаторного перебора возможных вариантов решения. Тем не менее среди этих методов наиболее выделяется ТРИЗ, как наиболее формализованный и наукообразный метод. Остановимся немного поподробнее на нем.
Автором ТРИЗ является Г.С. Альтшуллер, который начал работу над ней в 1946 году, а первая публикация появилась в 1956 году. За это время автор ТРИЗ проделал большую работу по анализу тысяч изобретений. Он обобщил работы тысяч изобретателей, и в результате на свет появился свод методов для решения задач и усовершенствования технических систем. Данная методология ставит перед собой цель формализовать и усовершенствовать изобретательский процесс, сделать его более предсказуемым и ускоренным.
Определенных успехов этот метод действительно добился, в 70-х и 80-х годах он начал активно применяться в СССР, а в 90-х годах многие известные фирмы, такие как Samsung, Hewlett Packard, LG и многие другие, начали применять его в своей инновационной деятельности. После чего появился запрос на цифровизацию использования данной методологии, начали появляться группы разработчиков ПО, которые создали программные пакеты, использующие ТРИЗ.
Наиболее коммерчески успешный из них назывался «True Machine». Однако начиная с конца 2000-х годов интерес со стороны крупных инновационных компаний к ТРИЗ и программных продуктам на ее основе постепенно начал угасать. В качестве критики ТРИЗ выступают доводы о слабой научности методологии и ограниченности подхода.
Далее поговорим об актуальности задачи генерации решения технических задач с позиции использования методов автоматической обработки больших объемов данных, а именно машинного обучения. Информационные системы, позволяющие тиражировать опыт квалифицированных специалистов имеют название экспертных систем, и чаще всего применяются в сферах, где важен эмпирический опыт специалистов, смысловая и логическая обработка информации. Их разработка мотивирована прежде всего возможностью повысить производительность труда и приблизить решения менее квалифицированных пользователей системы к уровню решений эксперта.
В последнее время появляются разработки в области экспертных систем, основанные на достижениях в области машинного обучения. Тенденция по внедрению машинного обучения в экспертные системы, отчасти связана с экспоненциальным ростом информационного и культурного фонда, которое успело породить человечество за время своего существования.
Если обратиться к патентной данным на русском языке, которые доступны в открытых источниках, то объем информации будет весьма внушительный, на рисунке представлена диаграмма отражающая количество патентов, зарегистрированных в разные года.
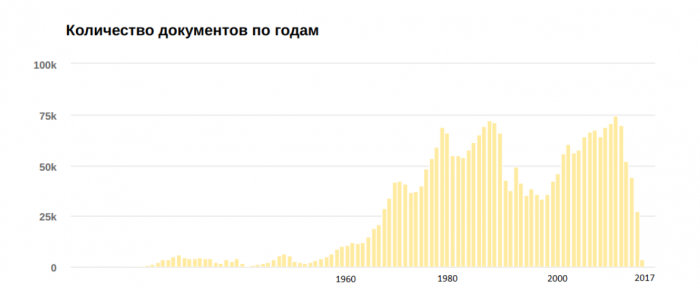 Количество патентной информации по годам
Количество патентной информации по годам
Если сложить эти цифры, то получится, что количество патентов доступных на русском языке равняется приблизительно 3 миллионам. Становится понятно, что этот большой объем данных будет трудно проанализировать вручную, на это могут уйти человеко-годы. Между тем этот анализ мог бы помочь выявлению взаимосвязей между техническими задачами и паттернами для их решения.
Поговорим о том, почему данную задачу стоить решать, используя методы машинного обучения. Зададимся вопросом: для каких задач в рамках экспертных систем уместно использовать машинное обучение? Обычно такие задачи обычно удовлетворяют следующим критериям:
- Задачи, где требуется большой объем ручной работы по настройке длинных списков правил.
- Задачи, где есть большой объем данных на входе, который необходимо обработать, после чего выдать ответ в виде информации в преобразованном виде.
- Получение сведений о крупных объемах данных, в которых присутствуют сложные взаимосвязи и их трудно выявить при ручной аналитике.
Исходя из этого можно сделать вывод, что использование методов машинного обучения для генерации решений технических задач будут вполне уместны. Стоит отметить тот факт, что интеллектуальная обработка текстовых данных в данный момент переживает второе рождение, связанное в первую очередь с появлением нейронных сетей новой архитектуры трансформер. Поэтому в рамках данной публикации будем использовать именно эту архитектуру.
Сбор данных
В большинстве задач по обработке естественного языка исходные данные не предоставляются в готовом виде, чаще всего их нужно собрать самостоятельно. Для этого прибегают к различным средствам в зависимости от задачи.
- Источник(и):
- Войдите на сайт для отправки комментариев
