Игры искусственного разума: атаки на модели машинного обучения и их последствия
Блог компании Криптонит. Насколько легко обмануть искусственный интеллект? Можно ли подстроить аварию с участием автопилота, или скрыться от «умных» камер, оставаясь у всех на виду? Специалисты компании «Криптонит» провели масштабное исследование, в котором сравнили 10 вариантов атак на модели машинного обучения (ML, от англ. Machine Learning). Их выводы помогут реалистичнее взглянуть на уязвимости систем компьютерного зрения, определить границы применимости различных атак на модели ML, оценить их вычислительную сложность и наиболее эффективные подходы к реализации.
Сегодня мы доверяем ИИ выполнение задач, связанных с жизнью, здоровьем и свободой людей. Искусственный интеллект анализирует ЭКГ и рентгеновские снимки лучше врачей, следит за дорогой внимательнее любого водителя, распознаёт в толпе объявленных в розыск лиц быстрее полицейских. Несмотря на принципиально разные сферы применения, в основе различных реализаций ИИ лежат однотипные модели машинного обучения (ML).
Машинное обучение кажется современной технологией, но его развитие берёт начало в 1950-х годах от научных работ Артура Сэмюэла (автора Checkers-playing, одной из первых самообучающихся программ в мире) и американского нейрофизиолога Фрэнка Розенблатта. Среди советских учёных большой вклад в развитие данного направления внесли В. Н. Вапник и А. Я. Червоненкис. Конкуренция двух сверхдержав привела к тому, что к семидесятым годам были разработаны все ключевые элементы ML: метод опорных векторов (один из наиболее классических способов «обучения с учителем»), методы автоматического дифференцирования, нейросетевая модель зрительной коры «неокогнитрон» и искусственные нейронные сети (ИНС) различных типов.
Одна из самых популярных архитектур в машинном обучении — свёрточные нейросети (CNN, от англ. convolutional neural network). История их создания начинается в восьмидесятых годах прошлого века, но на тот момент это были чисто теоретические концепции. К девяностым годам CNN уже были детально описаны в том виде, каком мы их знаем сейчас. Уже тогда было понятно, как их нужно программировать и обучать, однако популярными CNN стали только в 2010-х годах. Только в последнее десятилетие появились достаточно мощные аппаратные средства и возможность перенести на них давно известные алгоритмы. Также буму нейросетей способствовало появление больших и общедоступных датасетов — наборов обучающих данных.
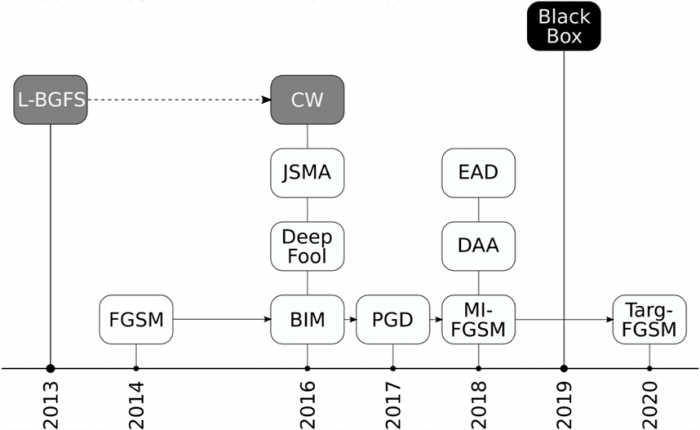 Так выглядит временная шкала появления различных типов атак на ML. Подробнее о каждом из них рассказываем ниже.
Так выглядит временная шкала появления различных типов атак на ML. Подробнее о каждом из них рассказываем ниже.
Первые публикации, в которых исследовалась безопасность моделей машинного обучения на основе ИНС, появились в 2013–2014 гг. В них были описаны атаки на свёрточные нейронные сети для распознавания изображений. В последующих работах была разработана модель угроз и постулировано, что атаки могут проводиться на различных этапах жизненного цикла ИНС: производство, внедрение или эксплуатация. Кроме очевидной цели нарушить работу модели ML, атака может выполняться с целью сбора информации о модели или наборе данных, использовавшихся при её построении.
Дизайн эксперимента
Мы сфокусировались на задаче выведения модели ML из строя путём подачи ей на вход специальным образом сформированных данных. Их ещё называют «вредоносные примеры» (adversarial examples). В последние годы появилась масса научно-популярных публикаций, в которых утверждается, что ИИ легко сбить с толку, едва заметно изменив свою внешность, или подменив один пиксель изображения. Мы решили проверить это и спешим поделиться результатами.
Просто показывать вредоносные примеры было бы не очень наглядно (они мало отличаются от исходника). Поэтому мы покажем возмущения, которые нужно наложить на исходный пример, чтобы получить из него вредоносный. Интенсивность возмущений обозначим в условных цветах.

В нашем исследовании мы использовали три общепринятых в информационной безопасности сценария:
- Атака типа white-box предполагает наличие полного доступа к ресурсам сети и наборам данных: знание архитектуры сети, знание всего набора параметров сети, полного доступа к обучающим и тестовым данным.
- Атака типа gray-box характеризуется наличием у атакующего информации об архитектуре сети. Дополнительно он может обладать ограниченным доступом к данным. Именно атаки по типу «серого ящика» чаще всего встречаются на практике.
- Атака типа black-box характеризуется полным отсутствием информации об устройстве сети или наборе обучающих данных. При этом, как правило, неявно предполагается наличие неограниченного доступа к модели, то есть имеется доступ к неограниченному количеству пар «исследуемая модель» + «произвольный набор входных данных».
Атаки black-box и white-box являются двумя крайностями. Первые очень сложны в реализации (это как решить уравнение с тремя неизвестными), а вторые имеют сугубо теоретическое значение. Они предполагают, что атакующий знает о выбранной нейросети и её обучении буквально всё. В реальной жизни это обычно означает, что атаку выполняет сам разработчик. Примеры таких атак могут быть очень зрелищными. Например, если атакующий обладает полной информацией о модели ML и средствах сбора данных, то атака может быть реализована с помощью физических объектов, например — очков, на оправе которых нанесён цветовой шаблон.
Мы протестировали различные библиотеки для создания вредоносных примеров. Изначально были отобраны AdvBox, ART, Foolbox, DeepRobust. Производительность AdvBox оказалась очень низкой, а DeepRobust на момент исследования была очень сырой, поэтому в сухом остатке оказались ART и Foolbox.
Эксперименты проводились на различных типах моделей ML. В статье мы демонстрируем самые наглядные результаты, полученные с использованием одной фиксированной модели на основе свёрточной нейронной сети и пяти различных атак.
- Источник(и):
- Войдите на сайт для отправки комментариев
