Учимся совершать правильные ошибки — краткое сравнение человеческого восприятия и мультимодальных языковых моделей
Блог компании Wunder Fund. Автор оригинала: Mayukh Deb. Представьте, что вы, совершенно один, отдыхаете в своём маленьком бревенчатом домике в лесу. Когда вы, декабрьским вечером, начинаете читать уже вторую книгу из списка «Книги недели», вы слышите поблизости чьи-то тяжёлые шаги. Вы бросаетесь к окну, чтобы посмотреть — кто это там прошёл. Через окно вы видите крупный силуэт кого-то, кто, кажется, покрыт мехом. Существо исчезает в тёмном лесу сразу за вашим крыльцом.
Информация, которую вы получили из окружающей среды, прямо-таки кричит вам: «Я встретил снежного человека!». Но ваш здравый рассудок говорит, что это был, с гораздо большей вероятностью, просто слишком увлечённый путешествием турист, который прошёл мимо вашего дома.
Вы только что успешно совершили «правильную ошибку», предположив, что у вас за окном, вероятно, путешественник, несмотря на то, что имеющаяся у вас информация свидетельствует о другом. Ваш мозг нашёл «рациональное объяснение» исходной информации благодаря имеющимся у вас годам опыта жизни в лесу.
В этом эксперименте проводилось сканирование мозга испытуемых в то время, когда они смотрели на картинки, на которых был только «шум». Исследователи выяснили, что фронтальная и затылочная области мозга испытуемых проявляют активность в тот момент, когда испытуемые думают, что они видят в «шуме» лица. Эти области мозга считаются имеющими отношение к высокоуровневому мышлению, например — к планированию и к памяти. Подобный всплеск активности может отражать воздействие на восприятие ожиданий и опыта.
В соответствии с тем, что изложено в работе It’s Bayes All The Way Up, была построена модель восприятия, включающая в себя «рукопожатие» между «нисходящим» и «восходящим» аспектами человеческого восприятия. В упрощённом виде эту модель можно описать так:
- «Нисходящий аспект»: Обрабатывает данные и выводит заключения на основании исходной информации, получаемой от органов чувств. Пугающий силуэт + вой = снежный человек.
- «Восходящий аспект»: Добавляет поверх исходной информации «слой мышления», который принимает и использует «прежние знания» (то есть — опыт, полученный в прошлом) для того чтобы осмысливать данные. Пугающий силуэт + вой = слишком увлечённый путешествием (или пьяный) турист.
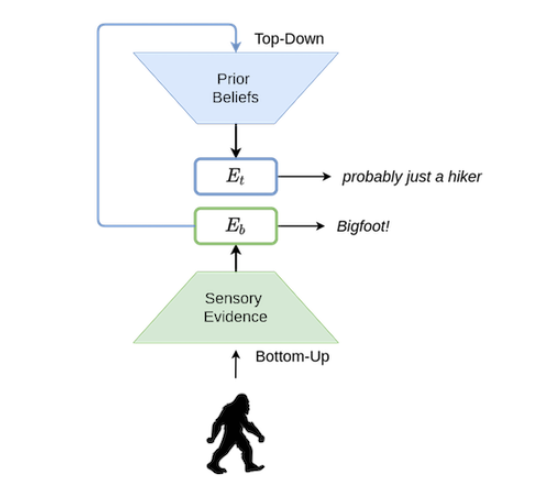 Рис. 1. Схема модели человеческого восприятия из этой работы
Рис. 1. Схема модели человеческого восприятия из этой работы
Дети гораздо более склонны «поддаваться» непосредственным выводам, которые делаются на основе «восходящего» восприятия. Это из-за того, что у их «нисходящего» восприятия недостаточно «опыта/обучающих данных», которые позволили бы этому восприятию самообучиться и улучшить свои качества. В некотором смысле это позволяет говорить о том, что их «модель мира» не так совершенна, как у взрослых.
Интересным последствием сильного «нисходящего» восприятия является способность людей видеть всякое, вроде животных и лиц, в облаках (парейдолия). Эта странная особенность мозга может показаться нам чем-то вроде «бага», но для наших предков, которые были охотниками или собирателями, это было скорее не «багом», а жизненно важной «фичей». Для них безопаснее было предполагать, что они видят где-то лицо, даже тогда, когда на самом деле никакого лица там не было. Это было средством защиты от хищников в дикой природе.
Что собой представляют мультимодальные языковые модели?
Большие языковые модели, вроде GPT-3/Luminous/PaLM, это, упрощённо говоря, системы для предсказания следующего токена. Их можно рассматривать как (большие) нейронные сети, которые обучены классификации следующего слова/знака препинания в предложении, что, выполненное достаточное количество раз, как представляется, позволяет генерировать текст, который согласован с контекстом.
Мультимодальные языковые модели — это попытка приблизить то, как подобные языковые модели воспринимают мир, к восприятию мира человеком. Большинство современных популярных моделей глубокого обучения (вроде ResNets, GPT-Neo и т.п.) отличаются узкой специализацией либо на задачах машинного зрения, либо на языковых задачах. Модель RestNet хороша в извлечении информации из изображений, а языковые модели, вроде GPT-Neo, хорошо генерируют тексты. Мультимодальные языковые модели — это попытка сделать так, чтобы нейронные сети воспринимали бы информацию и в виде изображений, и в виде текста. Достигается это благодаря комбинации моделей компьютерного зрения и языковых моделей.
Как работают мультимодальные языковые модели?
Мультимодальные языковые модели способны использовать знания о мире, закодированные в их языковой модели, в других областях, наподобие обработки изображений. Люди не просто читают и пишут. Мы видим, читаем и пишем. Мультимодальные языковые модели пытаются имитировать эти процессы, адаптируя свои части, ответственные за обработку изображений, таким образом, чтобы они оказались бы совместимыми с «пространством эмбеддингов» их языковых моделей.
Одним из примеров подобных моделей является MAGMA. Это — GPT-подобная модель, которая может «видеть». Она способна принять на вход произвольную последовательность данных, включающую в себя текст и изображения, и выдать подходящий текст.
Эту модель можно использовать для генерирования ответов на вопросы относительно изображений, для идентификации и описания объектов, присутствующих на входных изображениях. А иногда она ещё удивительно хороша в деле оптического распознавания символов. Она, кроме того, известна хорошим чувством юмора.
- Источник(и):
- Войдите на сайт для отправки комментариев
