Tinkoff: Cracking AI Research
Блог компании TINKOFF. Автор: Сергей Колесников*. Машинное обучение давно вышло за пределы академий и развивается семимильными шагами в индустриальных лабораториях благодаря широкой применимости. Используя машинное обучение и искусственный интеллект во многих бизнес-процессах компании, мы решили пойти дальше и показать не только world-level AI-продукты, но и world-level AI-исследования от Тинькофф.
Рассвет AI в Тинькофф
В ноябре 2020 Тинькофф объявил о создании Центра Технологий Искусственного Интеллекта, который объединил все, что связано с машинным обучением и искусственным интеллектом. А в январе 2021 в этом центре появился отдел исследований.
Отдел исследований отличается от привычных продуктовых команд. Он развивает темы и направления, которые важны для области в целом. Применимость этих решений не сиюминутная, ее можно увидеть только спустя какое-то время. Основная задача отдела — показать лидерство Тинькофф в развиваемых Центром областях искусственного интеллекта, которые каждый день используются в продуктах компании.
Если успех продукта измеряется прибыльностью, то успех исследовательского отдела — научными публикациями. Чем больше публикаций и чем крупнее конференции и журналы, в которых они были опубликованы, тем лучше. Для AI-исследований есть три крупнейшие конференции: NeurIPS, ICLR и ICML. Публикация на них — огромное достижение для любой исследовательской группы. В этом году у нас таких публикаций было целых две, о них мы сегодня и расскажем.
Showing Your Offline Reinforcement Learning Work: Online Evaluation Budget Matters
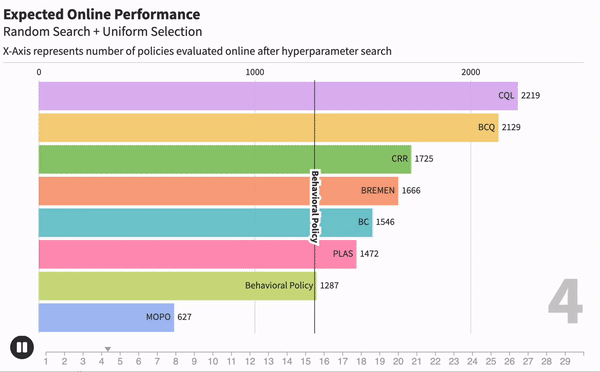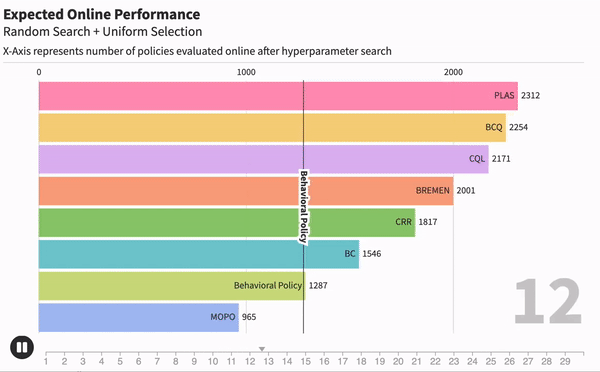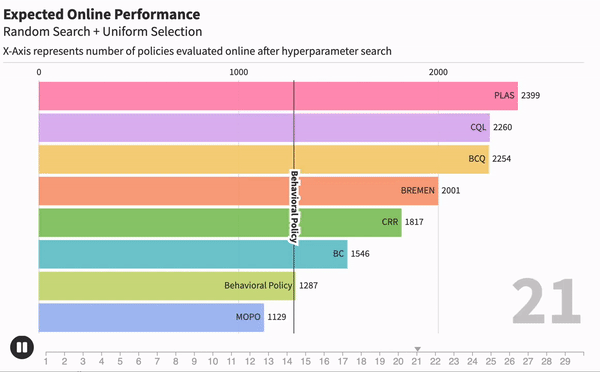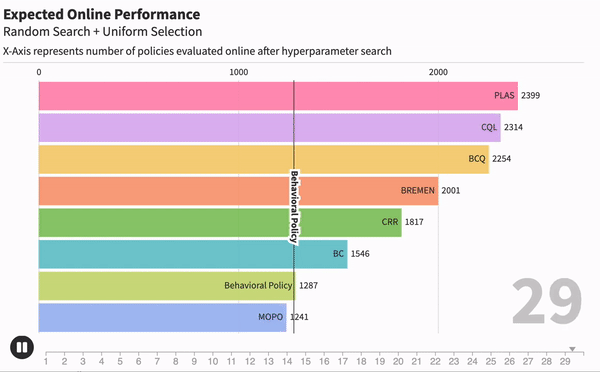
Когда мы занимаемся машинным обучением, очень важно понимать, насколько хорошо работает тот или иной метод. Для каждой модели могут существовать десятки метрик, которые оценивали бы ее. Например, возьмем модель текстовой классификации, чтобы находить негативные комментарии. Одной из метрик качества может быть точность работы — отношение правильных предсказаний ко всем сделанным предсказаниям.
Если рассуждения о том, как оценить саму модель, звучат достаточно понятно, то все становится сложнее, когда мы пытаемся оценить подход для обучения этой модели. Обученная модель — это результат комбинации множества выборов: можно использовать разные глубокие архитектуры, разные трюки при их обучении, разные способы подготовки данных и многое другое. Но как при таком разнообразии определить, что один подход лучше, чем другой?
Наивный подход к решению этой задачи заключается в том, чтобы взять метод к обучению модели, много раз изменить гипер-параметры обучения и сказать, что качество работы метода в целом равно качеству лучшей обученной модели. Такой подход широко используется в научных статьях, однако он имеет серьезный недостаток.
Рассмотрим два метода обучения: большую и сложную глубокую модель (А) и маленькую и примитивную модель (В). Если долго перебирать параметры для модели B, то в целом реально добиться качества лучше, чем у модели A. Значит ли это, что сложная и глубокая модель хуже? Не совсем.
- Источник(и):
- Войдите на сайт для отправки комментариев
