Нейросети хватило видео с монозвуком для создания бинауральной записи
Американские исследователи научили алгоритм превращать монофоническую запись звука в бинауральную, позволяющую слушателю испытывать эффект реалистичного объемного звука. Особенность метода заключается в том, что в качестве исходных данных алгоритм использует видеозапись, на которой он находит источник звука, что позволяет создать двухканальную аудиозапись, рассказывают авторы статьи , опубликованной на arXiv.org.
Кроме того, исследователи создали алгоритм, который разделяет аудиодорожку на каналы, соответствующие разным инструментам, используя для этого видеоряд.
Человек может определять не только сами звуки окружающего мира, но и примерное расположение их источников. Это возможно благодаря тому, что человек имеет два уха, разделенные определенным расстоянием, а также имеющие асимметричную форму. В результате, звук доходит до ушей не одновременно и с разной интенсивностью. Для воссоздания подобного объемного восприятия мира существует метод бинауральной записи, при котором используются два микрофона, расположенные с разных сторон полноценной модели головы или внутри двух моделей ушей.
Исследователи из Facebook AI Research разработали метод, позволяющий воссоздать бинауральную запись, имея в качестве исходных данных только одноканальную аудиозапись и видеоряд.
Алгоритм, разработанный исследователями, состоит из двух основных компонентов — сверточных нейросетей U-Net и ResNet. Сначала стереоаудиозапись объединяется в монозапись, которая подвергается оконному преобразованию Фурье. На этом шаге алгоритм создает из исходного сигнала его спектрограмму, которая подается на первый слой U-Net. Параллельно с этим соответствующий кадр из видео подается сначала на нейросеть ResNet-18, где превращается в характеристический вектор. Он, в свою очередь, подается на один из слоев U-Net. Таким образом, в этой сети происходит аудиовизуальный анализ, в результате которого образуется новая спектрограмма. После этого алгоритм производит обратное оконное преобразование Фурье, получает новую моноаудиозапись, из которой рассчитывается два канала — правый и левый.
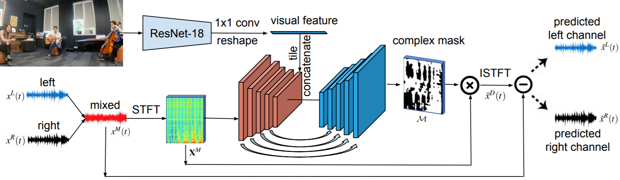 Схема работы алгоритма / Ruohan Gao, Kristen Grauman / arXiv.org, 2018
Схема работы алгоритма / Ruohan Gao, Kristen Grauman / arXiv.org, 2018
Для обучения алгоритма исследователи собрали установку, состоящую из бинаурального микрофона (он состоит из двух микрофонов, с наложенными на них моделями ушей) и закрепленной ниже камеры. Благодаря этой установке авторы смогли собрать датасет, состоящий из записей игры на музыкальных инструментах с общей продолжительностью 6,3 часа. Нейросеть ResNet была обучена не на этом наборе, а на известном датасете распространенных объектов ImageNet.
 Установка для сбора данных / Ruohan Gao, Kristen Grauman / arXiv.org, 2018
Установка для сбора данных / Ruohan Gao, Kristen Grauman / arXiv.org, 2018
Исследователи проверили эффективность своего метода, сравнив его с тремя его вариациями и еще одним методом, разработанным другими исследователями. Для этого они использовали четыре датасета, собранные из роликов с улиц, клипов в YouTube и других данных. Проверив работу алгоритмов на этих данных, они сравнили спектрограммы сигнала, полученного в результате работы алгоритма, и реального стереосигнала. Новый метод достиг наименьшей разницы на всех четырех датасетах. Такие же результаты алгоритм показал в исследовании предпочтений добровольцев.
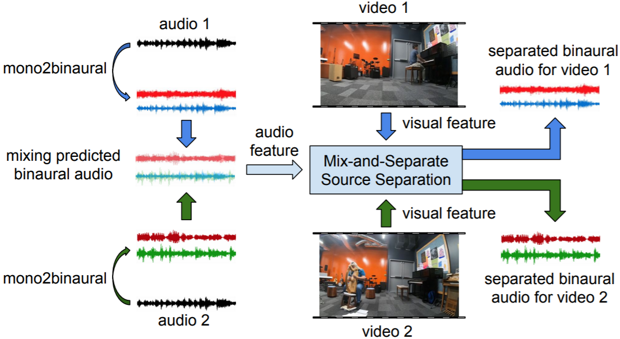 Схема работы алгоритма для разделения аудио на каналы с разными инструментами / Ruohan Gao, Kristen Grauman / arXiv.org, 2018
Схема работы алгоритма для разделения аудио на каналы с разными инструментами / Ruohan Gao, Kristen Grauman / arXiv.org, 2018
Также исследователи использовали свой алгоритм для разделения сигналов, принадлежащих разным инструментам. Но в качестве исходных данных он получал уже пару созданных бинауральных аудиозаписей и видеороликов. В результате алгоритм научился выполнять и эту задачу. Результаты работы обоих алгоритмов можно увидеть на демонстрационном видеоролике.
- Источник(и):
- Войдите на сайт для отправки комментариев
