Томография позволила «развернуть» древние обугленные свитки
Специалисты из Италии и России смогли прочитать часть текста обугленного свитка из древнеримского города Геркуланума, который был уничтожен во время извержения Везувия в 79 году нашей эры. Для того чтобы не повредить свиток, его виртуально «развернули» с помощью рентгеновской фазово-контрастной томографии. Несмотря на то, что это не первая подобная работа, ученые утверждают, что они смогли прочесть рекордно большой объем текста по сравнению с аналогичными работами со свитками из Геркуланума. Исследование опубликовано в виде препринта на сайте Arxiv.org, также о нем сообщает MIT Technology Review.
В 1752 году на территории древнего города Геркуланума была обнаружена вилла, в которой были найдены почти две тысячи папирусных свитков с древними текстами. Это единственная обнаруженная на сегодняшний день сохранившаяся античная библиотека. Из-за того, что она, как и близлежащие Геркуланум и Помпеи, была погребена под пеплом от извергающегося Везувия, свитки в той или иной степени обуглились или даже были уничтожены.
Часть из сохранившихся свитков были утрачены уже после обнаружения виллы: при разворачивании они разрушались. Некоторые из наиболее сохранившихся папирусов удалось прочесть с помощью специальной машины, медленно разворачивавшей свитки. В последние годы сразу несколько исследовательских групп смогли извлечь фрагменты текста из свитков, считавшихся нечитаемыми из-за их состояния. Это было сделано с помощью различных техник рентгеновской томографии. В частности, в начале 2015 года был прочитаны свитки из того же Геркуланума.
В новой работе ученым удалось увеличить разрешение сканирования и прочесть рекордно большой объем текста на греческом языке. Исследователи использовали метод рентгеновской фазово-контрастной томографии. Он основан не на поглощении, а на интерференции лучей в результате преломления в образце. Поскольку чернила немного увеличивают толщину папируса, это утолщение и использовалось для обнаружения текста.
Видео, наглядно объясняющее распознавание текста в свитках с помощью томографии
Для того чтобы обрабатывать данные с синхротрона, ученые разработали специальную программу, которая создает трехмерную модель свитка и «разворачивает» его, превращая в плоское изображение. Поскольку папирусный лист обычно состоит из двух слоев сырья с перпендикулярным расположением полосок, компьютер мог «исправлять» неравномерно скрученный свиток, исходя из перпендикулярного расположения волокон.
Сначала ученые проверили методику на самостоятельно изготовленных свитках из папируса, которые были подвергнуты бескислородному нагреванию и другим действиям, позволившим создать относительно точную имитацию настоящих древних свитков. Исследователям удалось прочитать предварительно написанный на них текст, поэтому они обратились в Национальную библиотеку Неаполя и получили на время исследований два свитка.
 Inna Bukreeva et al. / Arxiv.org, 2017
Inna Bukreeva et al. / Arxiv.org, 2017
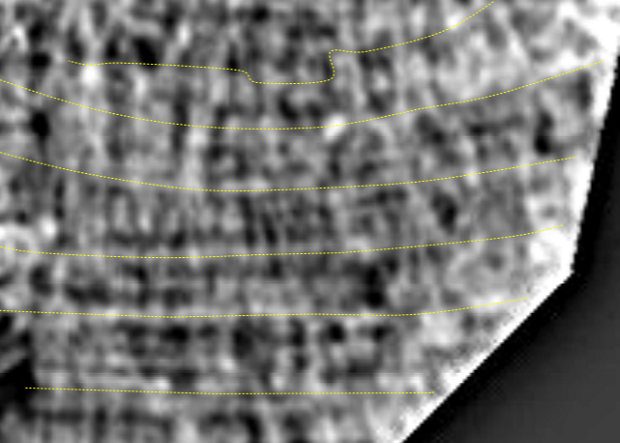
В результате ученым удалось прочесть несколько фрагментов текста размером до 14 строк. В частности, были идентифицированы части слов или даже целые слова. К примеру, ученые предполагают, что одно из найденных слов представляет собой «ἀκο̣ήν», что означает «слышать» или «слушать».
 Пример изображения текста, полученного учеными. Inna Bukreeva et al. / Arxiv.org, 2017
Пример изображения текста, полученного учеными. Inna Bukreeva et al. / Arxiv.org, 2017
В последние годы несколько раз удавалось прочесть и другие неразворачиваемые свитки, к примеру фрагменты Пятикнижия, обнаруженные в национальном парке Эйн-Геди на территории Израиля. Сначала был прочитан лишь фрагмент, а через год удалось распознать весь текст.
Автор: Григорий Копиев
- Источник(и):
- Войдите на сайт для отправки комментариев
