«Мы научили машину выбирать лучший вариант»
Четырнадцатого сентября компания «Яндекс» запустила новую версию своего переводчика. Главным нововведением является внедрение гибридной системы, которая умеет выбирать между нейронным машинным переводом и статистической моделью. Об особенностях и перспективах нового Яндекс.Переводчика, а также о том, сможет ли машинный перевод вытеснить живых переводчиков, мы побеседовали с британским компьютерным лингвистом и разработчиком Дэвидом Талботом — новым руководителем сервиса.
N + 1: Дэвид, прежде чем мы начнем разговор о вашей новой системе гибридного перевода, хочу задать общий вопрос. Если говорить о задачах, которые стоят сегодня перед разработчиками машинного перевода вообще, то какую из них вы назвали бы самой сложной?
Дэвид Талбот: Машинный перевод активно развивается последние двадцать лет, однако ему еще далеко до идеала — ведь даже люди, чтобы стать хорошими переводчиками, учатся годами.
Думаю, что самая главная проблема на нашем пути — это контекст, понимание которого необходимо для успешной коммуникации. Профессиональный переводчик, к примеру, не просто владеет двумя языками, чаще всего он также является специалистом в какой-то области. Владение конкретной областью знаний, понимание того, что именно ты переводишь, осознание различий между языками — все это пока еще очень сложные задачи для компьютера.
Люди довольно неплохо могут пользоваться двумя языками. Например, если вы переводите с английского на русский, вы понимаете, когда вам нужно изменить порядок слов, когда они должны быть согласованы, например, по роду. А для компьютера это очень сложная задача.
Память или анализ
Хорошо, тогда давайте перейдем к деталям вашей разрабботки. Обычно машинный перевод строится на основе статистической модели. Однако в последнее время все более популярны становятся нейросети. В чем, по-вашему, состоят преимущества нейросетей перед статистическим подходом к переводу?
В машинном обучении используются огромные базы данных, на которых происходит обучение модели. Это относится как к статистическому машинному переводу, так и к нейросетям. Но у разных видов машинного обучения — разные возможности.
Статистический метод использует миллиарды предложений из параллельных корпусов, то есть огромное количество предложений, переведенных людьми. По сути, этот метод основан на запоминании конкретных фраз, поэтому он требует огромного объема памяти, но сами предложения, их структуру, машина при этом не понимает. Такой метод можно рассматривать в качестве некоего «умного словаря», только вместо слов в нем целые фразы. Его преимущество состоит в том, что переводчик способен запоминать любую информацию, которую «видел» всего один или два раза.
Однако статистический метод порой дает сбои, когда разные фрагменты текста требуется собрать вместе. Например, если вы посмотрите на старую версию Яндекс.Переводчика (и на многие другие машинные переводчики), то заметите, что переведенные им фразы могут быть плохо согласованы друг с другом. В русском, например, если у существительного будет неправильный падеж, то в предложении могут появиться два подлежащих. И все из-за того, что статистический машинный переводчик не воспринимает предложение целиком.
Революционное новшество, на которое способны нейросети, как раз и заключается в том, что машинный переводчик на их основе натренирован «видеть» все предложение целиком. Благодаря своей способности понимать контекст он может определить, что вот это слово — подлежащее, а следующее за ним — уже нет. Конечно, он не обладает лингвистическими знаниями как таковыми, он по-прежнему «видит» просто набор слов, но он способен понять структуру отношений между ними. Именно поэтому переведенный с его помощью текст становится более естественным, в нем лучше согласованы слова.
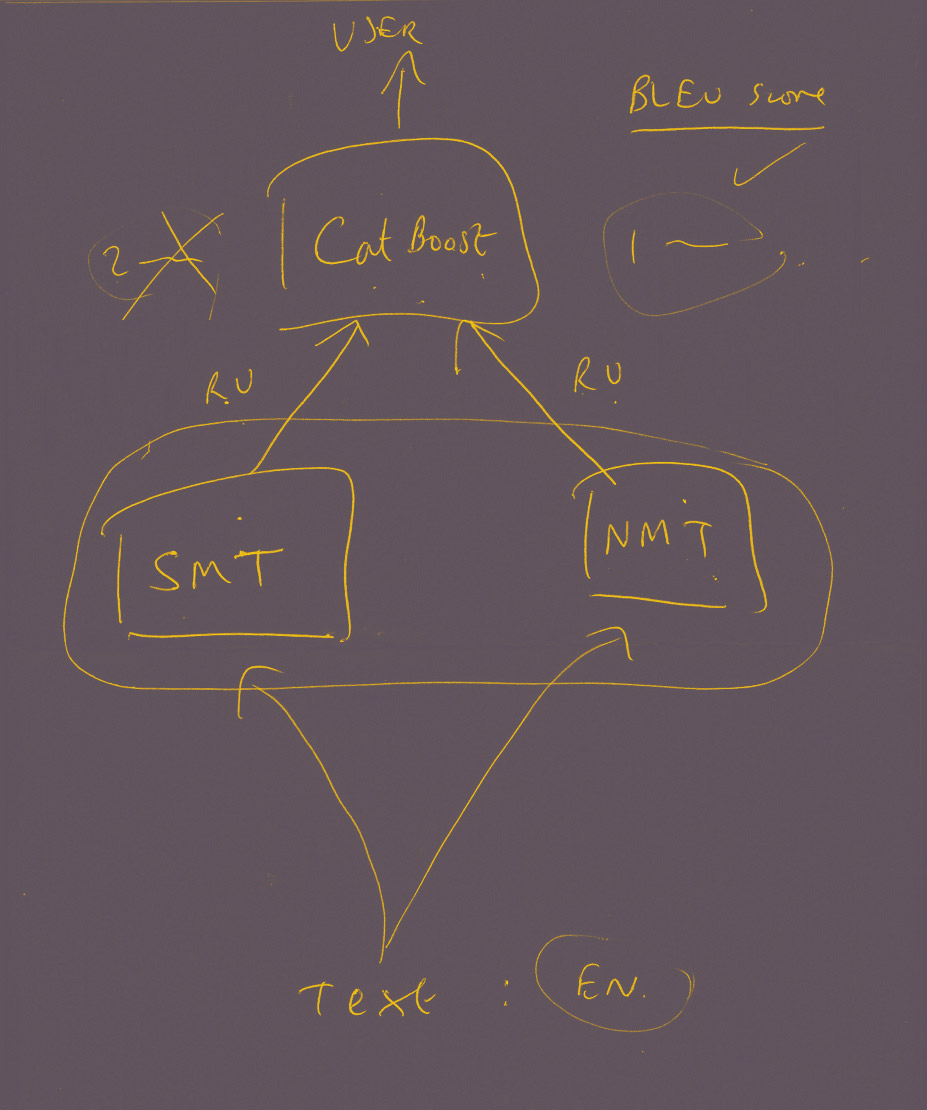
Чтобы объяснить нам, как работает новая гибридная система машинного перевода Яндекса, Дэвид Талбот нарисовал пояснительную схему. На ней видно, как (снизу вверх) исходный текст на английском языке попадает в систему, где его одновременно переводят на русский статистическим методом (SMT — statistical machine translation) и методом, основанным на применении нейросетей (NMT — neuronal machine translation). После этого классификатор CatBoost оценивает обе версии перевода в соответствии с системой BLEU. В итоге пользователь (User) увидит ту версию, кторая наберет больше очков (BLEU score; на схеме — правая, выполненная нейросетью), а вторая версия (левая, статистическая) будет отвергнута.
В новой версии Яндекс.Переводчика имеется функция, которая позволяет сравнить перевод новой гибридной и статистической версии — так пользователи смогут увидеть, что именно поменялось и насколько стало лучше.
**Существуют ли такие аспекты перевода, в которых подход, основанный на использовании нейросетей, проигрывает статистическому?*&
Да, конечно. Машинный перевод на основе нейросетей лучше учится на словах, которые видит часто — именно поэтому ему нужно очень много примеров. Но, например, если такому переводчику попадется название какой-нибудь компании, которое он прежде «видел» всего несколько раз, то его перевод может оказаться неправильным. Поэтому мы решили использовать оба подхода, нейросетевой и статистический, вместе: их сотрудничество оказалось весьма эффективным. Такая модель перевода и называется гибридной.
Память плюс анализ
Как она работает?
Наша гибридная модель просто переключается между двумя подходами. На практике это происходит так. У нас есть две модели — нейронная и статистическая. Переводчик на входе получает текст и пропускает его через обе модели. Затем CatBoost, наш собственный алгоритм машинного обучения, действует как классификатор, выбирая лучший вариант на основании входных данных. Обычно мы ожидаем, что нейронный перевод будет лучше, но иногда он дает неверный результат. Тогда классификатор в режиме реального времени выбирает статистическую модель.
Насколько я знаю, мы создали первый общедоступный машинный переводчик, который использует гибридный подход. Мы уверены, что он гарантирует лучшее качество, чем оба составляющих его подхода по-отдельности.
То есть классификатор может *только *выбрать одну из двух моделей?
Пока что да. Однако мы разбиваем текст на более мелкие составляющие, в зависимости от объема входного текста. Если текст достаточно большой, то некоторые предложения в нем могут быть переведены при помощи нейросети, некоторые — при помощи статистического метода, и в готовом тексте нельзя будет отличить один метод перевода от другого.
Намерены ли вы связать эти две модели более тесно?
Разработанная нами гибридная модель — довольно простой способ использовать два подхода одновременно. Но существуют и другие.
Нейронный машинный переводчик, как уже было сказано, иногда выдает на выходе странные фразы. Не очень понятно, почему он так поступает; скорее всего, получив на вход что-то, что редко попадалось ему в обучающей выборке, он решает дать на выход какие-то случайные слова, и иногда они не имеют абсолютно никакого отношения к переводимому тексту. Это частая проблема нейронного машинного перевода. А статистическая модель может ограничить эту случайную выдачу.
Сейчас два наших метода перевода работают как две независимые системы. В будущем мы надеемся научить их более тесному сотрудничеству.
Как именно CatBoost выбирает лучший вариант перевода?
Сперва обе модели — и нейронный, и статистический машинный переводчики — тренируются на огромном количестве текстов из параллельных корпусов. Затем они сами производят большое количество переводов. Потом наступает очередь обучаться классификатору. В его распоряжении имеются как примеры машинного перевода, выполненные обеими моделями, так и небольшой объем референтных примеров — переводов, выполненных людьми (они тоже взяты из параллельных корпусов). На основании референтных примеров классификатор учится понимать, в каких случаях машинный перевод максимально приближается к «человеческому» образцу, в каких случаях ему удается набрать максимальное количество очков BLEU — системы оценки качества перевода, которая применяется к обеим нашим моделям.
BLEU (bilingual evaluation understudy) — это алгоритм для оценки качества машинного перевода, который определяет количество слов, совпадающих в переводе системы и эталонном переводе предложения. В качестве коэффициента BLEU Яндекс.Переводчик использует процент совпавших n-грамм (где n ≤ 4).
Вот как это работает. Предположим, у нас есть на входе какое-то предложение и мы переводим его с помощью обеих моделей. Если бóльшая часть слов из одного варианта перевода соответствует словам, которые были в обучающей выборке, то классификатор выбирает именно этот вариант и запоминает особенности, сделавшие этот перевод хорошим.
И наоборот, классификатор отбрасывает вариант, если он плохой. Например, частая проблема нейронного перевода — это повтор слов. Если в переведенном предложении повторяются слова, значит, такой перевод нам не подходит — и классификатор делает выбор в пользу статистической модели.

Перевод и метафоры
Правда ли, что одна из самых сложных задач для машинного переводчика — это передача выразительных языковых средств, например метафор?
На данный момент не собрано достаточного количества данных для того, чтобы научить компьютер понимать такие языковые средства. Соответственно, их перевод действительно является очень сложной задачей. Но метафора — это тот уровень языка, который сегодня не столь важен для машинного перевода. Сначала мы должны добиться правильной передачи основного лексического значения.
Возможно, в будущем перевод абстрактных единиц языка станет основной и самой сложной задачей для машинного перевода. Как вы думаете, возможно ли в таком случае применение таких лингвистических теорий, как, например, теория концептуальных метафор?
Теория концептуальных (когнитивных) метафор — это теория когнитивной лингвистики, в соответствии с которой любое абстрактное понятие обязательно описывается через конкретное. Примером такой метафоры может быть сочетание времени и денег: мы тратим время так же, как мы тратим деньги, а драгоценные часы хранятся, как банковские вклады. Эта теория, однако, распространяется не только на язык, но также, по мнению авторов, и на формирование нашего сознания.
В начале развития машинного обучения, в конце девяностых годов, считалось, что у статистического метода машинного перевода — колоссальный потенциал, и к началу нулевых он действительно стал очень популярен. Но в большинстве случаев исследователи считали лишним прибегать к лингвистическим моделям для его улучшения, так как существовали другие способы добиться высокого качества перевода, более эффективные на первом этапе — требующие меньше человеческих ресурсов и дающие лучшие результаты. Когда потенциал применения данных был исчерпан и рост качества замедлился, лингвистические модели начали использовать — и это дало хорошие результаты.
В последние годы многие системы используют машинный перевод, основанный на нейросетях, — но, опять-таки, без привлечения лингвистических моделей; сперва необходимо использовать потенциал данных. Я уверен, в скором будущем в индустрии начнут использовать и лингвистические модели для нейросети, однако, это вопрос времени, пока что это требует бóльших ресурсов и сложнее.
В нашей гибридной модели машинного перевода используются некоторые лингвистические модели — в основном, синтаксические. Но пока что они применяются в статистической модели, а не в нейронной.
Они основаны на контекстно-свободных грамматиках?
Нет, на грамматике зависимостей. Контекстно-свободные грамматики более популярны в англоязычных лингвистических сообществах, а грамматика зависимостей — в русскоязычных, а также, например, во Франции и Чехии. Такой подход более естественен для описания языков, в которых нет строгого порядка слов в предложении, потому что он помогает обозначить роль отдельных слов, а не их порядок.
Человек плюс машина
Какова вероятность того, что машинный перевод достигнет совершенства и живые переводчики останутся без работы?
Думаю, что скорее живые переводчики станут чаще прибегать к помощи машинных. До недавнего времени качество машинного перевода было не на высоте. Например, правка текста, переведенного машинным способом, могла занимать даже больше времени, чем тот же перевод, выполненный человеком самостоятельно. Именно поэтому профессиональные переводчики обычно выступают против машинного перевода. Людям легче понять и воспроизвести ту информацию о тексте, которая недоступна компьютеру — например, стилистические особенности оригинала. Компьютер этого пока не умеет.
Но вообще машинный перевод предоставляет взаимовыгодные возможности: не только человеку видны ошибки компьютера, но и компьютер может подсказать человеку, что тот где-то ошибся. Таким образом, они могут учиться друг у друга. Да, люди нередко опасаются, что искусственный интеллект оставит их без работы. Но я думаю, что компьютер не заменяет человека, а расширяет его возможности. Скорее всего, в будущем люди будут переводить с других языков быстрее и чаще, чем сегодня, но определенно не прекратят этого делать.
Как вы думаете, машинный перевод будет способствовать сохранению редких языков?
В Великобритании, откуда я родом, говорят как минимум на одном малом языке — на валлийском. Это кельтский язык, на нем говорят в основном в Уэльсе, число носителей — около семисот тысяч. Я знаю, что валлийцы с опаской относились к машинному переводу. В Уэльсе все общественные вывески и вся открытая информация должны быть доступны и на английском, и на валлийском. Когда появились машинные переводчики, умеющие работать с валлийским, многие организации начали использовать их вместо живых переводчиков — и возникло немало проблем.
Все же мне кажется, что машинный переводчик с английского на валлийский полезен тем, что с его помощью в интернете появилось больше информации на валлийском. Также он очень полезен тем, кто учит язык — и это, кстати, касается всех малых языков.
Пожалуй, главное, что в наших силах, — это как раз помочь желающим изучать малые языки. Скажем, это могут быть люди, родившиеся в семье носителей малого языка, которые сами немного владели им в детстве, но потом забыли. Они могут воспользоваться онлайн-переводчиками, чтобы вспомнить этот язык и начать изучать его систематически.
Важно также работать вместе с носителями, желающими сохранить свой язык. Сейчас мы с помощью таких людей стараемся собрать данные для обучения нашей системы, чтобы улучшить качество машинного "перевода с редких языков.

И последний вопрос. Известно, что до перехода в Яндекс вы работали в Google. Что повлияло на ваше решение сменить место работы?
Я переехал в Россию вместе с Google около четырех лет назад — работать над голосовым поиском в московском офисе компании. В то же время я начал преподавать в ШАД (Школе анализа данных, созданной «Яндексом»). Я прочитал там курс лекций о машинном переводе, и это был очень интересный и приятный опыт. Примерно год назад я встретился с разработчиками «Яндекса», и оказалось, что в компании происходит много всего интересного.
У нас потрясающая команда. Алексей Байтин (прошлый руководитель сервиса) собрал уникальную команду профессионалов, каких в мире технологий очень мало. Невозможно отказаться от шанса поработать с такой командой во времена больших изменений в области машинного перевода. К тому же Яндекс — довольно маленькая компания по сравнению с той же Google, и это позволяет ей быть более гибкой. И мне это очень нравится.
Беседовала: Елизавета Ивтушок
- Источник(и):
- Войдите на сайт для отправки комментариев
